






























")

")



In a bold stride forward for generative AI, Panasonic Holdings has introduced Reflect-DiT, a new image generation technology that empowers artificial intelligence to critique and improve its own output in real time. Developed in collaboration with Panasonic R&D Company of America (PRDCA) and researchers at UCLA, Reflect-DiT promises more efficient, higher-quality images without needing endless rounds of training, according to Panasonic Newsroom Global.
Rather than relying purely on brute-force model scales or mass image sampling, the breakthrough lies in enabling the AI to “reflect” — to evaluate where its own rendering is lacking, describe the flaw in text form, and use that feedback loop to refine subsequent output. The result: smarter, cleaner, more accurate visuals generated faster than before.
Reflect-DiT has already drawn international notice: Panasonic and its collaborators will present the work at the prestigious ICCV 2025 conference, held in Hawaii in October.
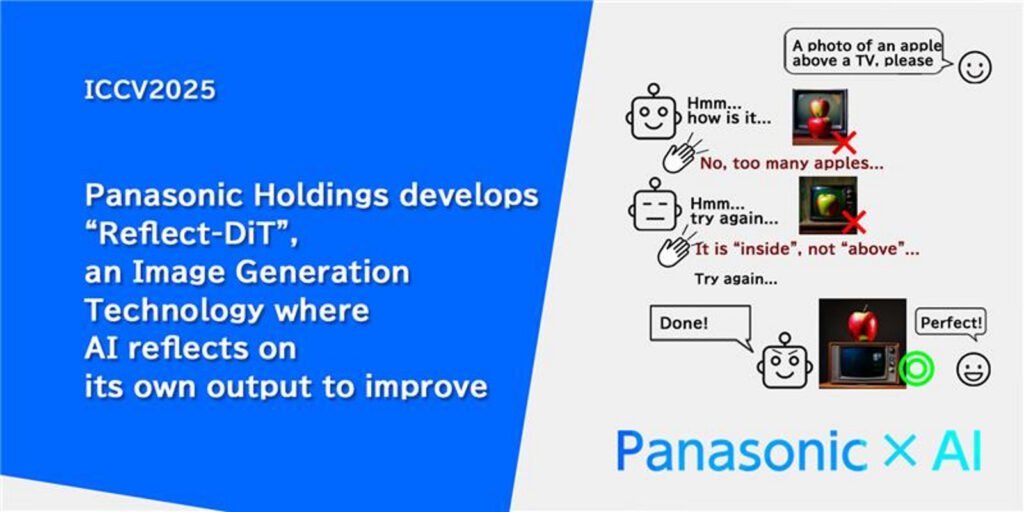
Table of Contents
How Reflect-DiT Works: AI That Thinks About What It Just Drew
The core innovation lies in embedding a feedback processing unit into the image generation pipeline. Here’s the simplified flow:
- The AI generates an initial image from a text prompt.
- A separate visual–language model (VLM) compares that image with the prompt, identifying mismatches or missing elements.
- The VLM produces textual feedback describing what needs improvement.
- That feedback is fed back into the generation model, guiding it to correct errors or deficiencies.
- The AI iterates, making adjustments on the fly.
This architecture establishes a self-reflection loop, allowing the system to refine its own output during inference rather than depending on repeated training cycles.
To evaluate performance, Panasonic compared Reflect-DiT’s method (called SANA-1.0-1.6B + Reflect-DiT) against a conventional “Best-of-N” approach (SANA-1.0-1.6B + Best-of-20). The results were striking: Reflect-DiT produced higher scores across metrics including object count, attributes, position, and overall fidelity — and did so using only about one-fifth as many candidate images as the conventional method.
In short, the system doesn’t just try many pictures and pick the best; it learns from its own mistakes in real time.

Why Reflect-DiT Matters — And Where It Could Go
Panasonic sees multiple compelling advantages:
- Efficiency: Achieving strong results with far fewer image proposals means less compute, less waste, and quicker output cycles.
- Quality: The feedback-enhanced loop helps eliminate glaring errors or omissions that simpler methods sometimes miss.
- Adaptability: Because the system is refining itself during inference, it can respond flexibly to edge cases or less common prompts.
In their forward-looking view, Panasonic suggests applications in areas such as architectural proposals, lighting design, real estate catalogues, or any domain where rapid visual mock-ups are required. A sales agent could generate a home layout, adjust lighting or textures interactively, and produce polished visuals on the fly.
To push adoption further, Panasonic intends to integrate Reflect-DiT into its broader AI initiatives, accelerating real-world deployment and continuing R&D to deepen its impact.
Perspective: Significance and Challenges Ahead
Reflect-DiT is part of a new wave within AI research: methods that refine on inference time rather than relying solely on larger datasets or deeper models. In the language domain, such “self-critique” or “self-improvement” steps have seen rising interest; Reflect-DiT is among the first to bring that concept into multimodal image generation.
Yet challenges remain:
- Robustness and generalisation: The feedback loop must reliably detect nuanced errors across a vast range of prompts — from simple object placement to subtle textures or lighting details.
- Latency trade-offs: The extra computation during generation must not slow down the process too much, especially for real-time or interactive use cases.
- Scalability: Deploying this across larger, production-grade models (beyond the test 1.6B scale) may require further engineering or optimisation.
- Bias and hallucination control: As with any generative model, ensuring that the system doesn’t reinforce its own misjudgments or hallucinate unjustified details is critical.
Still, the promise is tantalising: a system that, in effect, polishes its own work as it goes, reducing waste and improving outcomes. As AI moves beyond brute force to more self-aware architectures, Reflect-DiT may herald a new class of more efficient, agile generative models.

Conclusion
In the coming months, watchers in the AI space will look keenly at how Panasonic scales this capability, integrates it into real products, and whether the concept spawns imitators or extensions. If successful, Reflect-DiT could shift the balance in generative image AI — from “more compute, more samples” to “smarter self-reflection” as the path forward.
Join Our Social Media Channels:
WhatsApp: NaijaEyes
Facebook: NaijaEyes
Twitter: NaijaEyes
Instagram: NaijaEyes
TikTok: NaijaEyes


